Tech
Google Finally Sets Gemma Free: 05 Reasons the AI Community is Pivoting to Gemma 4


TL;DR
With the release of Gemma 4, Google has moved beyond incremental updates to spark a genuine open-source revolution. From the surprise pivot to Apache 2.0 to native audio on tiny edge models, here are the most impactful takeaways from Google's latest release.
A Quiet Thursday That Changed the Open-Source Race
In the high-stakes theater of Large Language Models, Google’s Gemma family has occupied a curious position. Despite racking up 400 million downloads since 2024, enterprise adoption was often throttled by "strings attached" in the licensing. Developers loved the performance but feared the lack of true digital sovereignty.
On a quiet Thursday in April 2026, the landscape shifted. By stripping away restrictive usage terms and delivering "frontier-class" reasoning in localizable packages, Gemma 4 marks the moment Google stopped playing defensive and started leading the open-weight charge.
Apache 2.0 and the End of "Open-Weight" Ambiguity
For a Senior Strategist, the most critical update in Gemma 4 is the transition to the Apache 2.0 license. Previous iterations were hampered by the "Gemma Terms of Use," which included a controversial "remote access" clause. This allowed Google the authority to restrict or disable usage remotely if policies were violated, a non-starter for enterprises requiring air-gapped security or vendor lock-in mitigation.

By adopting Apache 2.0, Google has eliminated these custom carve-outs and the risk of post-deployment rule changes. Hugging Face CEO Clément Delangue correctly identified this as a "huge milestone" for developer flexibility. This is a guarantee of sovereignty for teams building in sensitive or high-compliance environments.
The "E" Models’ Silent Power-Play
The introduction of the "Effective" (E) models, specifically the E2B and E4B, redefines what is possible in VRAM-constrained environments. To understand the E4B, we must look at the math: it possesses 8.0 billion total parameters, yet only 4.5 billion are effective during compute.
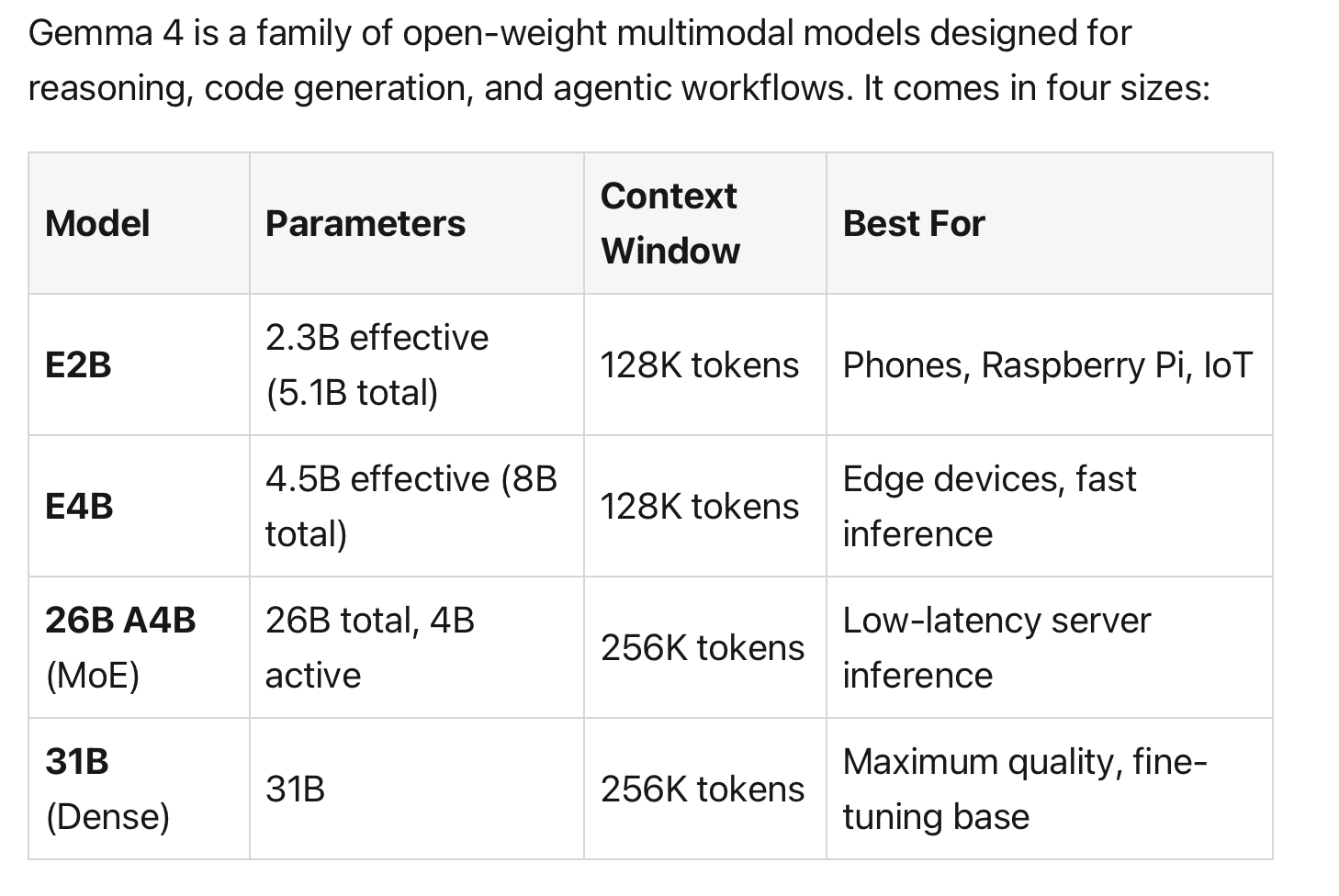
This efficiency is powered by Per-Layer Embeddings (PLE).
Rather than adding global parameters, PLE gives each decoder layer its own dedicated embedding table for every token. While this increases the static weight footprint (the VRAM required to hold the model), these tables are used only for lookups, keeping the active compute footprint remarkably low. This architecture allows these tiny models to process not just text and images, but native audio and video fully offline on hardware as humble as a Raspberry Pi or a smartphone, without the latency of bolted-on encoders.
Intelligence-per-Parameter: Beating Models 20x Larger
Google’s claim of "unprecedented intelligence-per-parameter" is validated by staggering gains in reasoning efficiency. The 31B Dense model now sits in the top tier of open models on the Arena AI leaderboard. Its 85.7% score on the GPQA Diamond benchmark (graduate-level science) is a formidable result, trailing Alibaba’s Qwen 3.5 27B (85.8%) by the narrowest of margins.
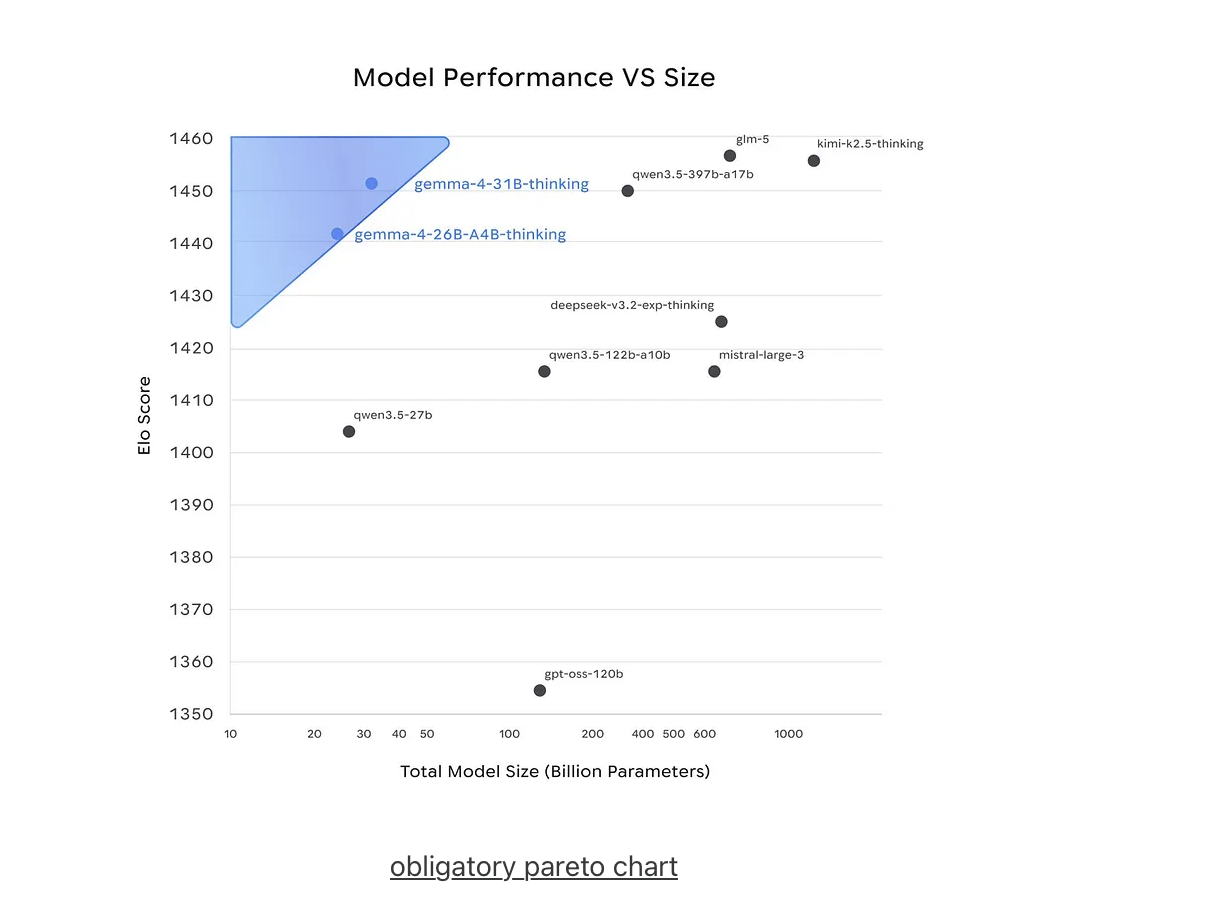
More impressive is the leap in mathematical reasoning: Gemma 3 27B managed a mere 20.8% on AIME, whereas Gemma 4 31B hits 89.2%—a 4x improvement in reasoning efficiency. This specialization is further showcased by TranslateGemma, a suite within the family that sets new standards for machine translation. By utilizing a two-stage SFT + RL pipeline with MetricX-QE and AutoMQM reward models, Google has proved that smaller, specialized models can outperform massive, generalist ones.
Mixture of Experts (MoE): 26B Logic at 4B Speed
The 26B A4B MoE architecture solves the industry’s most pressing trade-off: the cost of reasoning versus the speed of inference. This model utilizes 128 experts plus one always-active shared expert, with eight experts activated per token.

From a strategic perspective, hardware planning is key: while only ~3.8B–4B parameters are active for compute, the entire 26B weights must be loaded into memory (requiring approximately 48GB in BF16). For developers, this means the model offers the high-level logic and expansive knowledge of a 26B parameter system with the throughput efficiency of a 4B model, making it the ideal candidate for high-volume document processing and coding assistants.
The "Potato" Benchmark: High-Performance AI on a Raspberry Pi 5
The community’s "Potato" benchmarks provide the ultimate reality check for edge accessibility. Using a Raspberry Pi 5 with 16GB RAM, testers achieved a stable 4.52 tokens/second on text generation for the E2B-it Q8_0 model.

Achieving these production-usable speeds on a $100 SBC required a clever firmware tweak: a PCIe Gen3 override in the boot configuration to double the read speed of the attached M.2 SSD. This confirms that localized, private AI is no longer a luxury for those with H100 clusters; it is now a viable tool for IoT developers and hobbyists working on the workshop bench.
The Dawn of the Agentic Era
Gemma 4 is the first open-weight family designed specifically for the Agentic Era. With a 256K context window capable of ingesting entire codebases and a native Agent Development Kit (ADK), the platform is ready for autonomous workflows.
For the enterprise, the most high-impact feature is the GKE Agent Sandbox. This technology enables sub-second cold starts and can spin up to 300 sandboxes per second, allowing for the secure, isolated execution of LLM-generated code and tool calls at scale. With frontier-class reasoning now fitting on a local workstation—unencumbered by licensing restrictions—one must ask: Is the era of "closed-source" dominance effectively over?